on
Self-studying Python and Machine Learning: 2018 in review
Both for personal interest and professional development, I started to learn Python and machine learning concepts. This article summarizes my 2018 learning path.
Courses
In January, I completed the MOOC “Python 3: from the fundamentals to advanced concepts” that I started in November 2017. This MOOC, taught in French by two INRIA researchers, provided me with a very good introduction to the Python programming language: overview of the built-in types, functions, notions of OOP, …
Compared to the other courses I followed later, I think this one was the most complete, providing a progressive and detailed view of advanced notions like generator expressions, memory management, scoping rules, … I would definetely recommend it.
My lecture notes are here and the complete pdf of the MOOC is available here.
In March, I enrolled in a second MOOC on the FUN platform: Deep Learning.
Although I did not initially plan to follow this course, I spotted it when it came out and I thought it would be a good opportunity to learn more about this exciting topic.
The course was well structured (6 weeks, 6 chapters each): introduction to neural networks, CNN, historical perspectives and modern network architectures, applications, optimization, … Excepting a small demo of Keras, there was no programming in this course and all the evaluations where based on multiple choice questions. Yet, it was quite challenging and I learnt a lot.
Later during the spring, to further practice and revise some Python, I took the free version of the Learn Python Codecademy course. Nothing really new here compare to the Python course mentioned above, but the Codecademy platform is nice for learning in an interactive way. This course has been recently updated for Python 3, so it is a good resource to check.
During the summer, I followed the Udacity Intro to Machine Learning course. The reason I choose this course rather than the popular Andrew Ng’s one on Coursera is because it uses Python and the scikit-learn library (more precisely it uses Python 2, but I used Python 3 with code available on Github).
As the title indicates, this is an introduction. So, the course doesn’t go into too much details and some of the evaluations are really simple. To learn more about the underlying mathematical concepts, in parallel, I followed some of the videos from MIT 6.034. However, as shown in the picture below, I think this Udacity course offers a good overview of the ML concepts and of the iterative approach required to run an analysis.
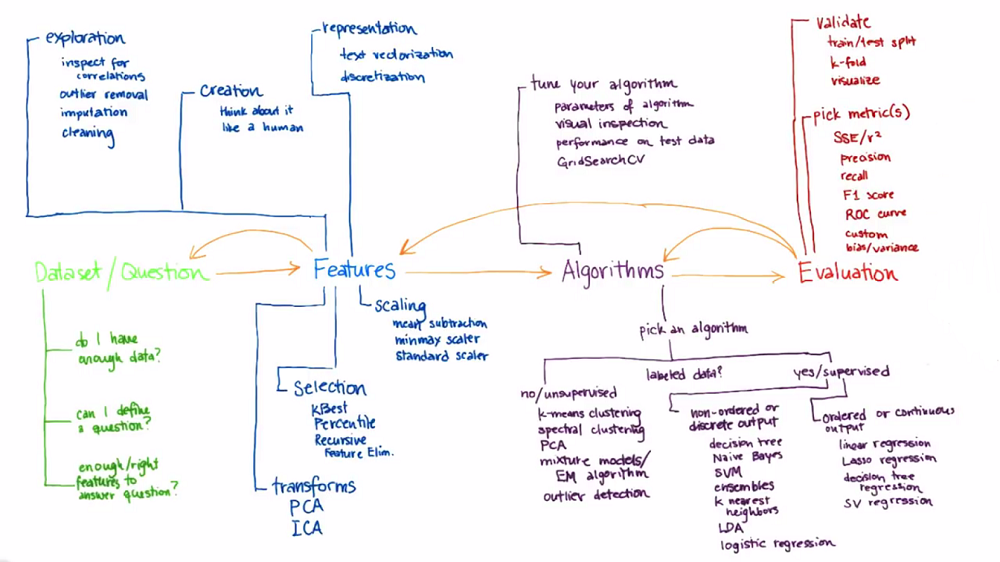
Udacity ML course overview (source: Udacity)
Then, from October to mid-December, over a 75-day streak, I have completed more than 30 DataCamp courses, including the ‘Data Scientist with Python’ track and several R courses.
It was good wrap-up, allowing me to review and strengthen the different topics covered previously, from the basics of Python programming to machine learning and even some bits of deep learning. Moreover, it made me more acquainted with data science libraries (Numpy, Pandas, or Bokeh) and I also discovered the basics of SQL.
Putting my new skills into practice
Considering the number of education platforms and online resources, it’s easy to get trapped on the ‘MOOC carousel’. While these courses are useful to understand the underlying concepts and discover best practices, learning by doing is essential.
In December, I discovered the kmnist dataset and decided to give it a try. I explored some machine learning and deep learning approaches, assessed their performance for classification, and dig a bit more into dimension reduction methods and visualization. It was only a 10-day streak, but it was nonetheless useful. I picked a lot of code here and there, but was able to understand it and adapt it to my needs. Hopefully, more will come in 2019.

Some examples of kana for the kmnist dataset (source: Clanuwat et al.)
The data science toolkit
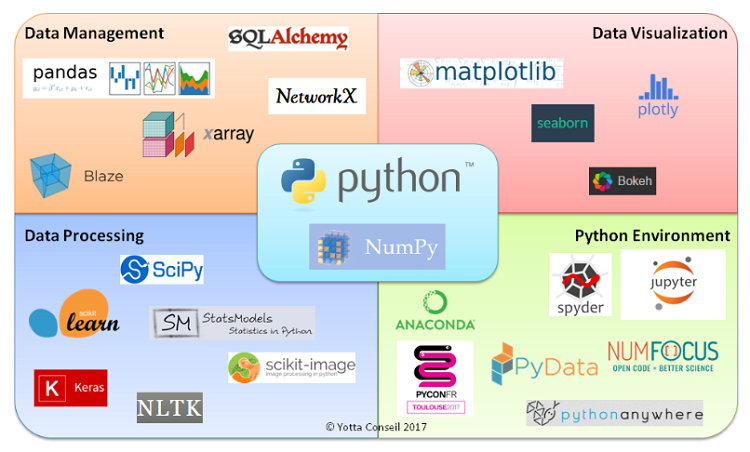
The Python data science ecosystem (source: Yotta Conseil)
Along the way, I have discovered several tools. I think the Python ecosystem is rather complex, but it also a very interesting and innovative field.
- First, I installed Anaconda and started to use Jupyter Notebooks.
- Then, I created new environments, including one dedicated to deep learning with TensorFlow and Keras installed, though I only scratched the surface of these libraries.
- As mentioned above, I have also learned the rudiments of libraries like numpy, pandas, matplotlib, and scikit-learn…
Scikit-learn is particularly easy to use with with a well-designed API and a fantastic documentation, making the coding part relatively simple (compared to the understanding of the methods, feature engineering, and all the analytical process).
- I had a quick look at google Colab, and will probably use it more often for more demanding computations.
- I tested the reticulate package to use Python from R (using the RStudio IDE).
- And finally, I have also become a big fan of vscode. For Javascript, R, and Python, vscode is very versatile and the interface is awesome.
Other
MOOC
I was interested in other moocs. In particular, I enrolled in two other courses: Fundamentals for Big Data on Fun and Linear Algebra on edX. I did not manage to fit them in my schedule. However, I have completed two other small courses: Privacy in a digital world and Introduction to Statistics with R. The former was very general and oriented towards a general audience, but useful in the RGPD context. The latter was a good refresher of basic statistics methods.
D3.js
After reading Scott Murray’s book (interactive data visualization for the web), I spent some time coding several visualizations. To learn further about D3.js and Javascript in general, I also checked Mike Freeman’s book and some of Curran Kelleher’s videos.
D3.js is amaizing. I hacked some examples in the past and I would really like to dive into it more deeply.
Books
Among the books I read, partially or completely, let’s mention:
- Data Science with Python, by Jake VanderPlas. An absolute must-read to learn about Python data science libraries.
- Hands-On Machine Learning with Scikit-Learn and TensorFlow, by Aurélien Géron. So far, the most complete book on machine learning I read. It covers a lot of methods.
- Deep Learning with Keras, by François Chollet.
- Introduction au Machine Learning, by Chloé-Agathe Azencott. A good book, in French, complementary to the previous ones since it focuses on the maths and methods and not on the code.
- Mike Freeman’s books: great resources, straight to the point on different topics (web development, data visualization, programming in general, …).
- Advanced R by Hadley Wickham.
- The Art of Readable Code by Dustin Boswell and Trevor Foucher. Recommended by Hadley Wickham, it is indeed a very inspiring book.
Conclusion
So, did I become a Python and machine learning expert with all these courses, books, and coding sessions? Definitely not. I still have a lot more to learn and to practice. But there is progress being made and I have developed a better intuition of how all these things work.
As said by Peter Norvig, being a good programmer or develop expertise in any domain takes time. Learning is a lifelong process!
Perspectives
What’s next? For 2019, I have the following objectves in mind:
- learn git and create a website/blog to more efficiently keep track of my achievements
- finalize this article so as to make it my first post
- refine and write about some personal works (mainly R-related)
- follow the fast.ai courses (machine learning and deep learning)
- more applications and personal projects
- more maths to better understand the methods
- more D3.js experiments
- more books (An Introduction to Statistical Learning by James et al., Python Machine Learning by Raschka and Mirjalili, Introduction to Machine Learning with Python by Mueller and Guido, …)